
一直在用Grafana,从未好好看过他的文档,这次发现还是有不少东西的。借着这次学习Grafana的机会,复习下指标相关的东西。
时间线
https://grafana.com/docs/grafana/latest/fundamentals/timeseries/
“时间线”(time series)是 a sequence of measurements, ordered in time, 通常同metric name+ label kvs来标识一个time-series,通常是折线图中的一条线。
时序数据库
time series database是时序数据库,其特征是数据是append-only并且以特定时间间隔写入,旧数据通常不需要变更。
时序数据库的的首要问题是:时间线膨胀——随着时间流逝,metric name+ label kvs的组合越来越多。组合越来越多,也被称为“高基数”。
由于时序数据的特征,存储sample的value时,第一个sample存原始值,后续存delta of delta,这样大部分值的占据的bit比较少,可以大幅减少存储空间。Gorilla压缩算法也是差不多的思想,主要用于时序数据。
时序数据还需要实现快速写入和快速检索时间线的name+label。技术上,通常使用WAL和LSM树(Memory table+SStable)
按时间聚合(降采样)
指标上报的interval通常比较精细,比如15s一个点。想看分钟粒度、小时粒度的指标时,就是将多个点聚合成一个点。也可以称为“降采样”,但是这侧重的是通过减少sample点来降低存储。
按时间聚合要考虑的是通过什么聚合函数来聚合,通常有
- avg
- sum
- count
- min
- max
需要根据指标的意义选择聚合函数。
grafana查询抽象
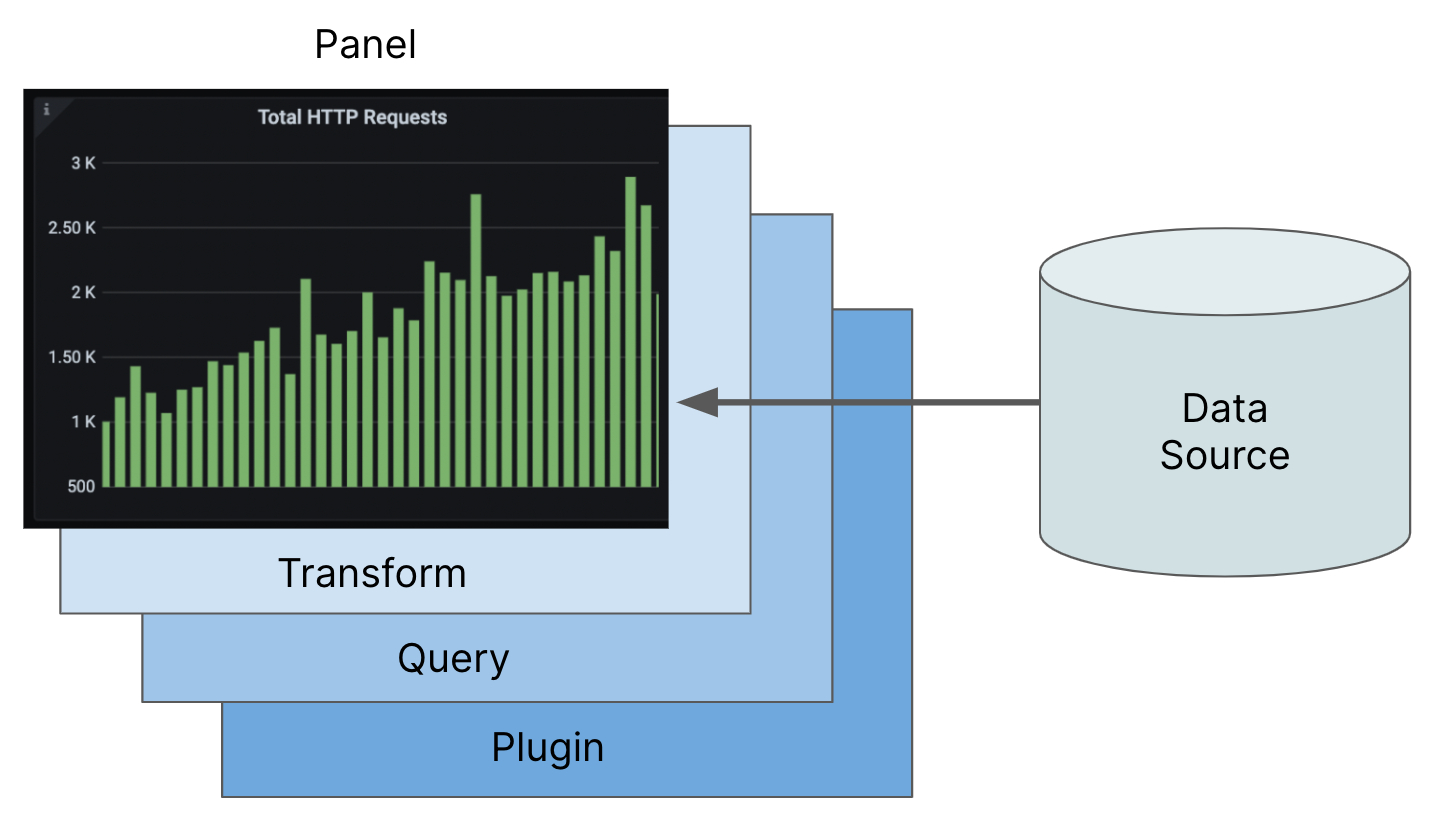
从数据源到plugin,plugin将原始数据变成 Data frame的格式,然后通过transform做一些转变(例如String转Date,字符串拼接),最终展示在pannel上,pannel也可以做一些定制。
整个流程在文档中的描述:After the data is sourced, queried, and transformed, it passes to a panel, which is the final gate in the journey to a Grafana visualization.