
“网络舆情爬取系统”是针对在一定的社会空间内,围绕中介性社会事件的发生、发展和变化,民众对社会管理者产生和持有的社会政治态度于网络上表达出来意愿集合而进行的计算机监测的系统统称。
背景
随着互联网的快速发展,网络媒体作为一种新的信息传播形式,已深入人们的日常生活。网友言论活跃已达到前所未有的程度,不论是国内还是国际重大事件,都能马上形成网上舆论,通过这种网络来表达观点、传播思想,进而产生巨大的舆论压力,达到任何部门、机构都无法忽视的地步。可以说,互联网已成为思想文化信息的集散地和社会舆论的放大器。
网络舆情是通过互联网传播的公众对现实生活中某些热点、焦点问题所持的有较强影响力、倾向性的言论和观点,主要通过BBS论坛、博客、新闻跟贴(回帖)、转贴等实现并加以强化。当今,信息传播与意见交互空前迅捷,网络舆论的表达诉求也日益多元。如果引导不善,负面的网络舆情将对社会公共安全形成较大威胁。对相关政府部门来说,如何加强对网络舆论的及时监测、有效引导,以及对网络舆论危机的积极化解,对维护社会稳定、促进国家发展具有重要的现实意义,也是创建和谐社会的应有内涵。
“网络舆情”是较多群众关于社会中各种现象、问题所表达的信念、态度、意见和情绪等等表现的总和。网络舆情形成迅速,对社会影响巨大,加强互联网信息监管的同时,组织力量开展信息汇集整理和分析,对于及时应对网络突发的公共事件和全面掌握社情民意很有意义。
需求
针对某特定热点问题,抓取各大网络社区的信息,是网络舆情爬取系统最重要的功能。
在互联网和信息大爆炸的时代,人们可以自由地选择平台表达自己的看法,如微博、百度贴吧、知乎、今日头条、腾讯新闻、搜狐新闻等等。而且我们国家是人口大国,网民数量在近20年稳步增长。目标平台多、网民规模大的情况给网络舆情系统的实现带来了的诸多挑战。因为目标平台多且目标网站改版周期短,网络舆情系统的设计必须保证功能的通用性,以应对网站突然改版。舆情爬取系统的功能需要与爬取业务松耦合。面对网民规模大的情况,舆情爬取系统必须实现分布式、集群化和规模可拓展。此外,还有一些爬虫系统通用的功能需求和非功能需求。
功能需求
- 爬取任务使用脚本语言定义,脚本可修改以确保爬取的业务逻辑发生改变时,不需要修改系统设计
- 爬取子任务的维护:一个完整的任务,往往需要扩展为多个子任务,例如一条舆情信息会涉及多个网页需要发起多次请求。需要正确处理深度、广度上的任务扩展
- 爬虫任务在分布式集群中消费和分配
- 解析和执行脚本语言,发起爬取任务,创建http请求。
- 实现http代理以防止针对ip的反爬策略
- http代理的选择策略:随机代理、同一代理、就近代理等等
- 网址链接URL的去重
- 爬取结果的解析和持久化
非功能需求
- 稳定。某一热点问题产生的舆情规模可能很大,要求爬取系统能够长时间稳定运行,以保证能稳定地获取大量的舆论信息。
- 高性能。信息的价值随时间减少,这要求系统必须快速抓取大量的舆情信息。
- 可维护。因为网络平台的设计迭代周期短,爬取脚本往往需要频繁修改,可维护性便十分重要。
系统初步设计
系统可以初步分为三大模块:任务脚本和脚本执行引擎、spider:http请求与响应的处理(httpclient和httpproxy)、爬取任务和url的维护和分配。
系统技术选型
- 任务脚本使用groovy编写,使用groovyscriptengine执行脚本
- http请求与http响应使用apache httpclient实现
- 使用自研http代理,通过加密确保请求与响应的数据安全
- 使用kafka消息中间件,向spider传递任务
- 使用etcd作为服务注册中心,管理http代理集群
系统部署图
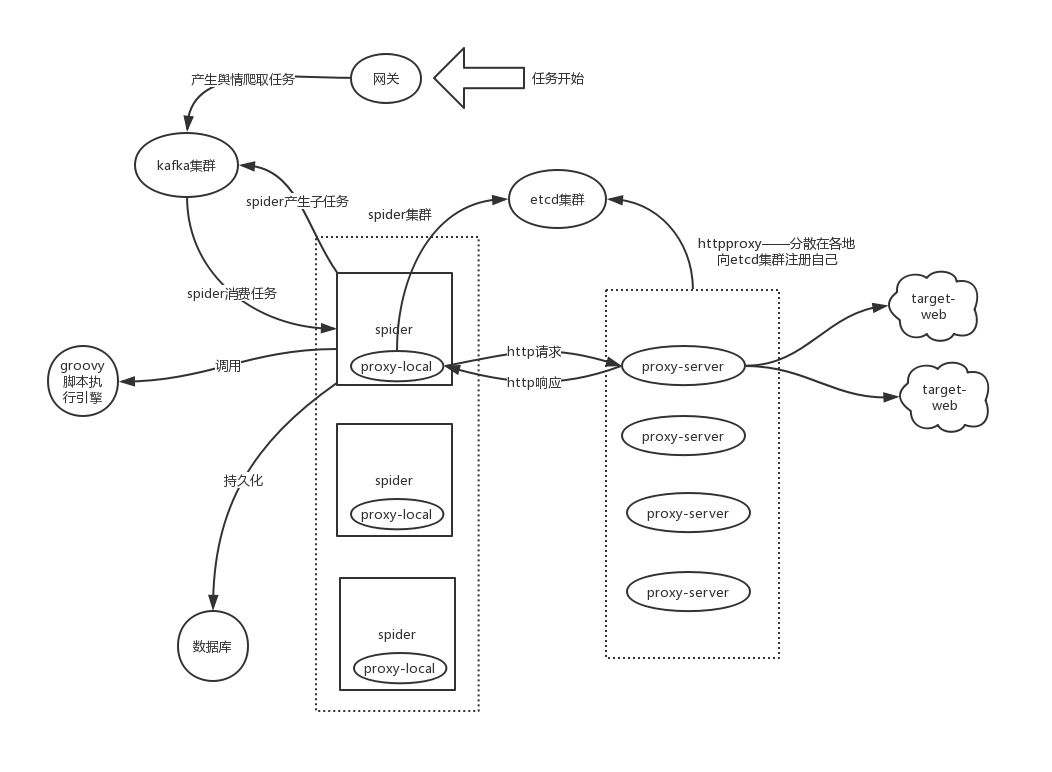
解释:
首先解释groovy脚本的职责。groovy脚本中定义了一个完整任务的执行流程,即一系列请求的创建及响应的解析和处理。因为一个任务一般会产生多次请求,因此groovy脚本要定义好每一次http请求,并对不同http响应产生不同的处理,例如:发起下一个http请求、失败重试三次、宣告单次任务失败、标志任务成功等等。
当任务调度开始时,例如发起一个任务:搜集关于“印巴冲突”的舆情
- 网关向kafka发送一个初始任务。针对今日头条平台产生:search"印巴冲突"。(每个平台都会产生一个初始任务)
- spider集群中一台实例消费了这个初始任务的消息
- 这一实例调用groovy执行引擎,找到对应的groovy脚本,创建search “印巴冲突"的http请求。
- spider执行这一http请求,并将请求转发到某一http代理,通过代理最终拿到search请求的响应。
- spider调用groovy执行引擎,处理该http响应,产生多个子任务:search出来的每一个条目对应一个子任务。
- spider将这些任务发送给kafka集群。
- spider集群中的实例消费这些子任务,处理流程同3、4、5、6,直到获取所有目标信息,标志单个子任务执行结束。
- 进行目标信息的持久化操作
重难点:groovy脚本及脚本涉及到的类的设计、spider设计与实现、kafka的学习和使用
可以简化的点:可以只使用kafka单机,无需集群;可以删除etcd集群和http代理部分;网关只是激发运行的作用,无需十分完善。
项目雏形
项目地址:EasySpider
拿英国的一个众筹项目网站练了下手,把所有项目爬下来放在了SEEDRS。共630多项目、450M+图文