
首先放参考文档
索引创建原则
- 尽量使用联合索引,尽量扩展联合索引,而非新建索引
- 最左前缀匹配原则,
- where语句中会一直向右匹配到范围查询(>,<,between,like>)
- 索引(a,b,c,d)——where中仅含有(b,c)不能使用索引,含(a,b,c)才能使用
- mysql有查询优化器,会调整你的where语句以尽可能地使用索引——如果有(a,b,c)这个索引,where a = 1 and b = 2 and c = 3中的a、b、c也可以使用到上述索引。
- 尽量使用区分度高的列作为索引,例如性别(0,1)的区分度没有姓名的区分度高
- 不要对索引column做function,例如:禁止from_unixtime(create_time) = ’2014-05-29’
- 尽量扩展索引,不要新建索引
- order by部分也可以使用到索引
EXPLAIN使用
EXPLAIN
SELECT *
from table
WHERE project_id IN ('a', 'b', 'c')
and project_type = 'xxx_type'
and user_type = 'xxx_user'
and user_id = '11111'
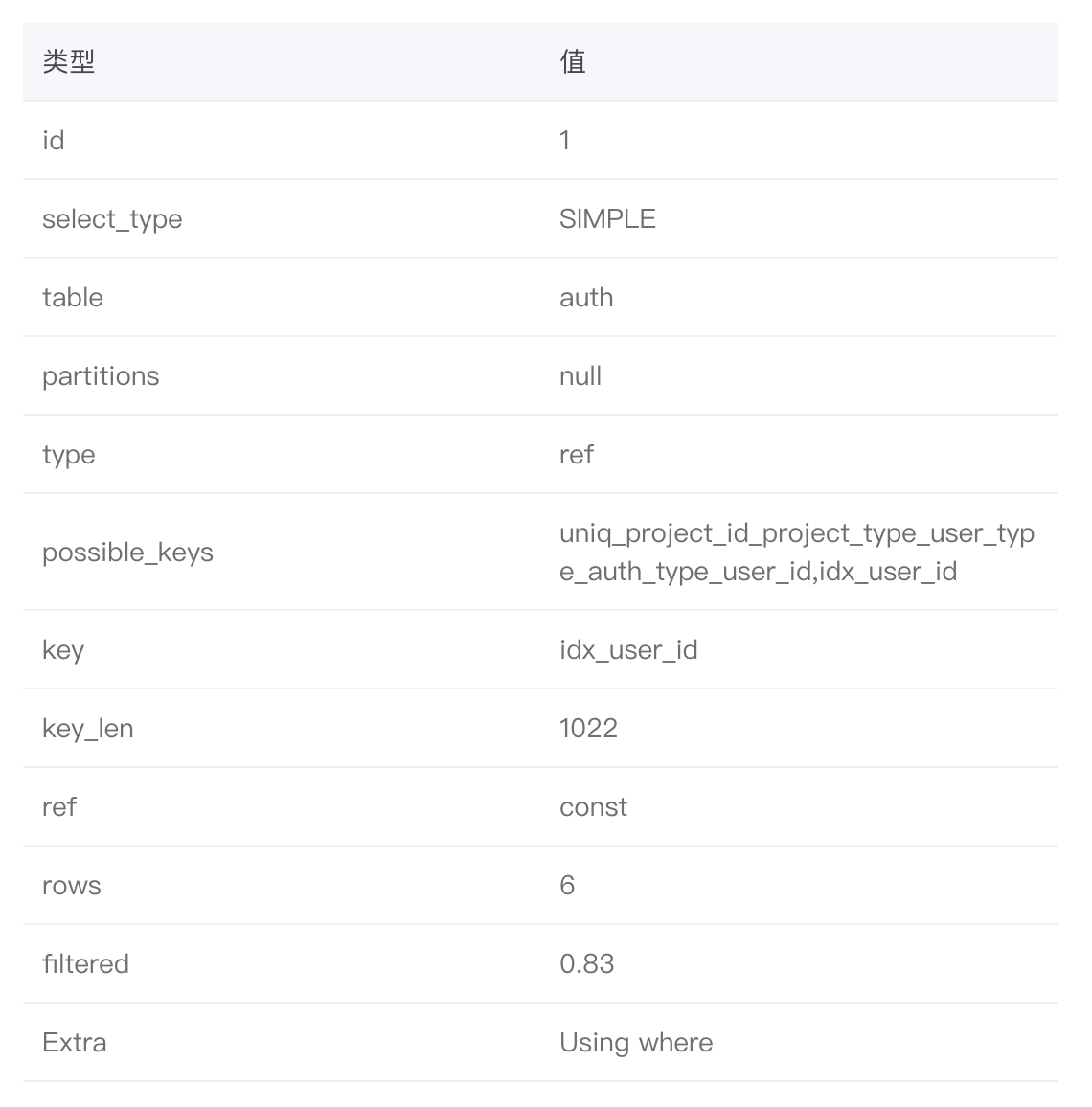
以上就是一个简单的EXPALIN使用的例子,接下来看看mysql官方文档怎么解释这些字段的。
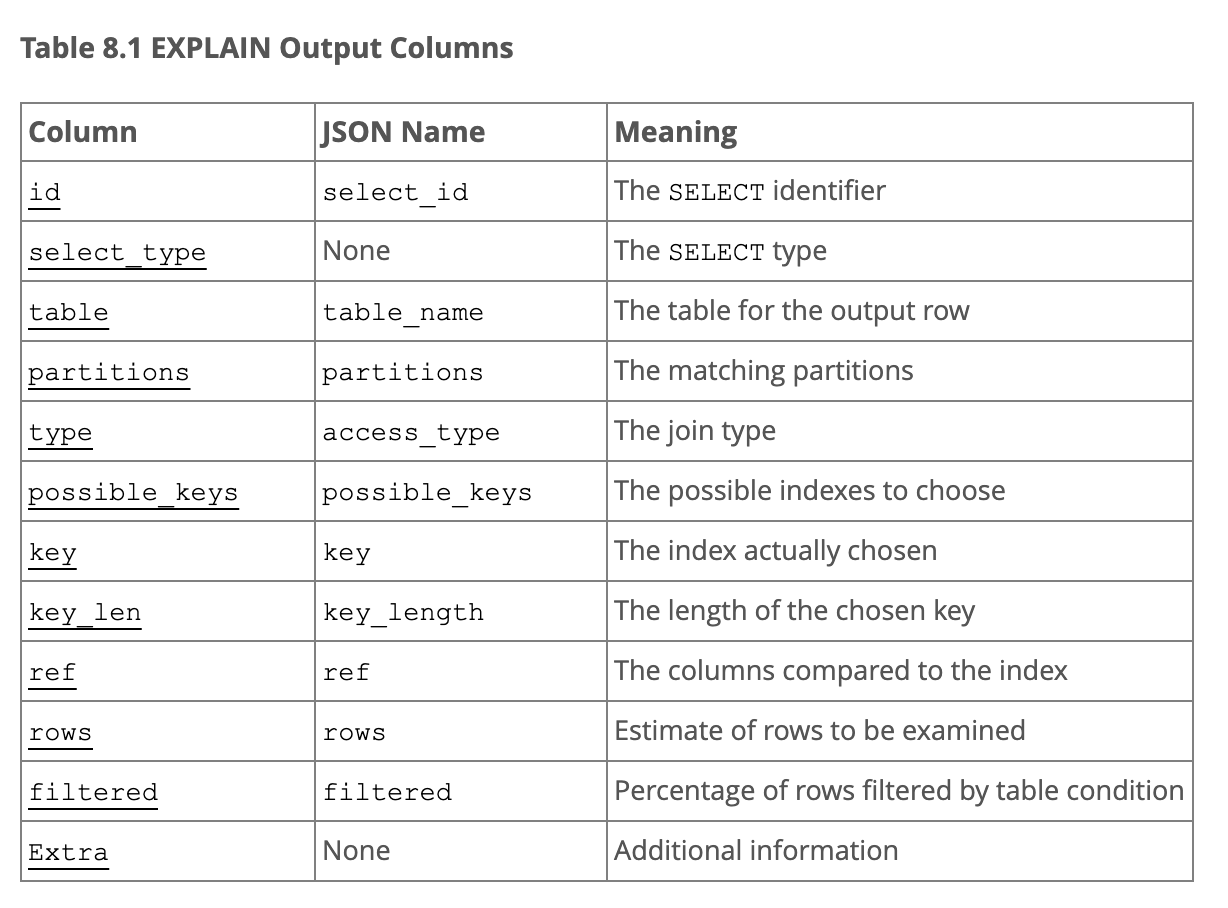
- id: 查询标识符,标示union联合查询这种有多个子查询
- select_type: 查询类型
- table: 查询的表
- partitions:查询的分区
- type: join类型,后面细讲(EXPLAIN Join Types)
- possible_keys: 可以使用的索引
- key: 真实使用的索引
- key_len: 使用的索引的长度,确定使用了联合索引的几个部分
- ref: 用于于索引列比较的值,例子:const,const,const 表示使用到了三个常量
- rows: 需要扫描的行数。在innodb中,这是一个估计值
- Extra:额外信息,下面细讲
type字段的详细解释(EXPLAIN Join Types)
join Types即使在单表也是有意义的,这个需要首先能理解
type字段的详细解析如下,从最优到最差排序
- system: 表只有一行(=system table)
- const:
【PRIMARY KEY / UNIQUE = const(s)】通过索引只能找到一行。两种情况:使用PRIMARY KEY找到唯一行,通过UNIQUE索引与常量做等于找到唯一行 - eq_ref:
【PRIMARY KEY / UNIQUE NOT NULL = 另一个表column(s)的值】join时,A表每次通过PRIMARY KEY或UNIQUE NOT NULL索引找到一行,与B表进行=比较。例子:
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
- ref:
A表使用索引 找到多个rows 与B表的column(s)对应。通过索引返回多行,返回的数量不多的情况下,是好的join type。例子:
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
- fulltext: 使用全文索引。对全文索引不咋了解
- ref_or_null: 在
refjoin的基础上加上对null值的扫描。例子:
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
- index_merge: 使用到index merge查询优化。使用到了多个索引。
- unique_subquery: 暂时不能理解
value IN (SELECT primary_key FROM single_table WHERE some_expr) - index_subquery: 暂时不能理解
value IN (SELECT key_column FROM single_table WHERE some_expr) - range: 跟ref比较像,对索引中的列使用了范围操作:=, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, or IN()
- index: 不好!扫描了索引的全部数据
- ALL: 不好!全表扫描
Extra字段解释
Extra也是比较有用的,展示sql执行的其他信息。
想要sql更快的话,关注并排除Using filesort和Using temporary
- Using filesort: mysql必须额外执行排序操作才能实现order by的语句。改进:把orderby使用到的column加入联合索引,这样排序就能利用到索引的顺序,就可以防止filesort了。更多order by优化,请看8.2.1.16 ORDER BY Optimization
- Using temporary: mysql必须创建临时表以完成查询。通常出现在既包含GROUP BY又包含ORDER BY的sql中