
新traceId格式
背景
当前端上使用一个long值的16进制的字符串作为traceId。目前存在两个问题:
1. 64位随机数的碰撞概率高,目前已经出现traceId碰撞的情况
2. 当前trace存储使用ClickHouse的Projection存储,其排序索引(主键)是traceId,即traceId在文件中是顺序的。当前traceId的生成规则是随机数,所以相近时间的traceId会分散在Data Part的不同部分,也就是要扫描的段比较多。如果让相近时间的traceId能处在一个局部,可以减少扫描的次数,从而减少负载和耗时。
目标
1. 降低traceId碰撞概率
2. 将时间相近的traceId尽可能存储在一起,从而减少扫描次数。
业内方案调研
UUID V1 (date-time and MAC address)
由3部分组成
● 时间:⾃1582-10-15 0点开始的第n个100nanoSecond
● 地址:机器mac地址
● 事件id(0-16383),单个tick⾥⾃增
单机每秒钟可以⽣成1638亿个id JDK中没有提供V1版本的UUID,需要参考开源的代码:
com.github.f4b6a3.uuid.factory.AbstTimeBasedFactory
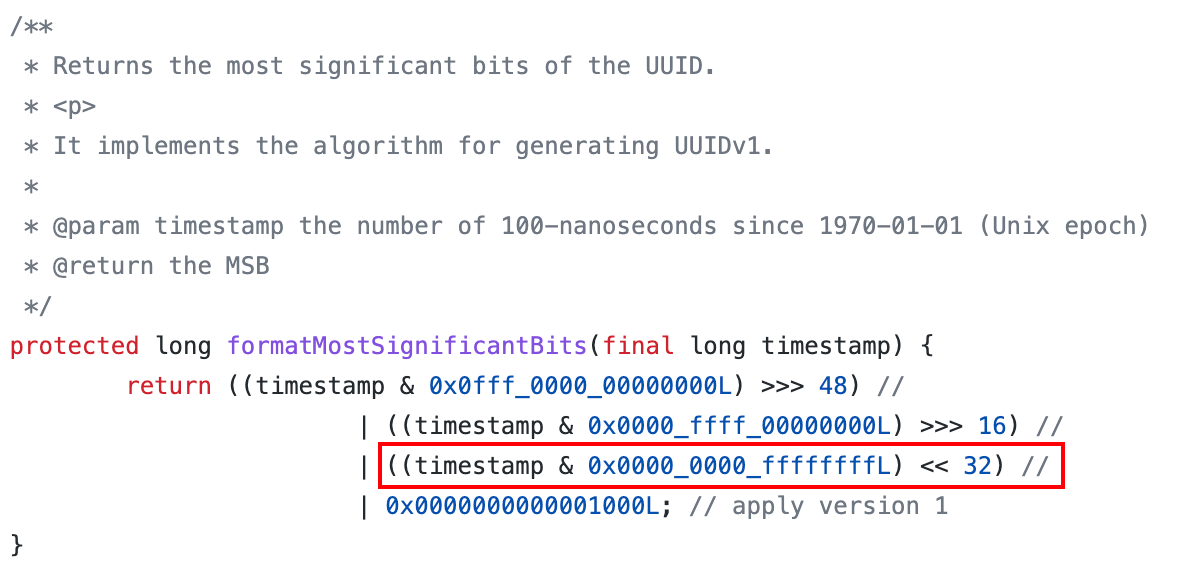
**问题:**虽然使用了时间作为字段之一,但是把时间分成了三段,并把最低的32位移位到了最高的32位,破坏了时间的有序性,详见下面的代码:
UUID V4 random
使⽤java.util.UUID#randomUUID⽣成,底层是使用SecureRandom获取2个16byte(long)。
问题:
1. SecureRandom获取可能会block线程。
2. 生成的ID不具备顺序性。
snowflake分布式唯⼀ID⽣成
traceId最基础的能⼒就是分布式ID,snowflake是业界⽐较认可的分布式唯⼀ID⽣成算法。snowflake算法的输出是64bit的long型数字,输⼊是相对时间(41bit)、机器id(10bit)、同机器内事件序号(12位)、⾸位 保持0(1bit,使id保持为正数)。
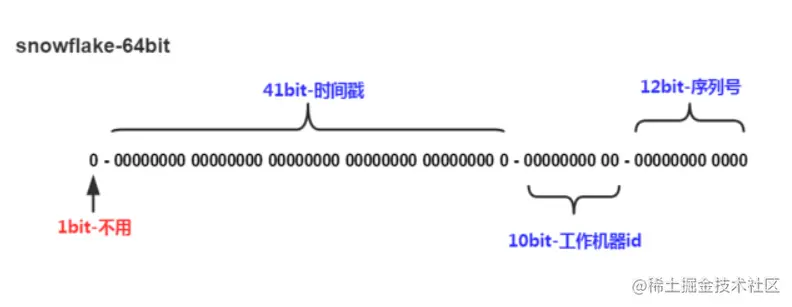
这个算法单机每秒内理论上最多可以⽣成1000*(2^12),也就是409.6万。
问题:
● 机器id占⽤10bit,只能标识1024个机器。
● 虽然各字段的位数可以调整,但是总共只能使⽤63位,调整空间不⼤。机器id占⽤位数增加则时间戳或者序列号就不够⽤了。
● 使⽤时间作为id的⼀部分。分布式情况下时间是不可信的,时钟不同步或者**“时钟回拨”**会导致id重复。
UidGenerator
这是百度开源的分布式唯⼀ID⽣成算法,整体也是snowflake的思想,在各部分的含义和位数上做了微调:
1. 时间戳表示秒,最多可⽀持约8.7年。原⽣snowflake这部分表示毫秒。
2. workerId为22位。同⼀台机器每次重启都会从mysql获取新的workerId。可以承载420w次重启。
3. 事件号为13位,最⼤为8192。意味着⼀秒最多⽣成8192个id,在⼀些场景下不够⽤。
4. 为应对特点3带来的并发度不⾼问题,允许“借⽤未来时间”.
⼀些问题:
1. 420万次重启仍然不够,需要考虑机器Id的复⽤才⾏,但这会带来复杂度提升。
2. 虽然时间借⽤的思想可以⼀定程度上缓解并发度不⾜的问题,但是单个workerNodeId也只能有2^(28+13)个事件id。假设在单机10000qps下,也只能保证2545天不需要重启获得新的workId。
3. 从本质上讲,UidGenerator只是snowflake的改良版,有⼀些优势但也带来了复杂度的提升,并引⼊了额外依赖。
leaf分布式唯⼀ID⽣成算法
分为leaf-segment和leaf-snowflake。
leaf-segment是使⽤数据库⾃增id来获取分布式唯⼀id,采⽤分段获取id和数据库分库分表来突破单机性能瓶颈和⾼可⽤
leaf-snowflake仍然是snowflake的思想,有点在于引⼊zookeeper更新机器时间,探测“时间回拨”的发⽣并进⾏fail-fast。
leaf的⽅案都需要引⼊额外依赖。SDK不适合依赖mysql,也不适合依赖zookeeper,暂不考虑leaf⽅案
OpenTelemetry
SDK中默认的是RandomIdGenerator(也可以⾃定义IdGenerator),使⽤的都是伪随机数。
traceId使⽤两个随机long,最终产⽣⻓度为32的16进制字符串(例如4e9da3d2deda7aa20c433fd1dd6cb48d)
spanId使⽤⼀个随机long,最终产⽣⻓度为16的16进制字符串(例如7b335f26aed48e08)
问题:不具备顺序性
SOFATracer/鹰眼
TraceId:服务器 IP + ID 产⽣的时间 + ⾃增序列 + 当前进程号 ,⽐如:0ad1348f1403169275002100356696
前 8 位 0ad1348f 即产⽣ TraceId 的机器的 IP,这是⼀个⼗六进制的数字,每两位代表 IP 中的⼀段,我们把这个数字,按每两位转成 10 进制即可得到常⻅的 IP 地址表示⽅式。
后⾯的 13 位 1403169275002 是产⽣ TraceId 的时间。
之后的 4 位 1003 是⼀个⾃增的序列,从 1000 涨到 9000,到达 9000 后回到 1000 再开始往上涨。
最后的 5 位 进程ID。为了防止出现 TraceId 冲突的情况,所以在 TraceId 末尾添加了当前的进程 ID。
这个方案仍然是相关信息的拼接,不同于snowflake系的区别在于最终输出不是long,⽽是string。
SkyWalking TraceId/segmentId
使⽤ 应⽤实例Id+线程Id+时间戳(毫秒)+事件号(0-9999),使⽤英⽂句号分割。
仍然是相关信息的拼接,不同于snowflake系的区别在于最终输出不是long,⽽是string。
TraceId生成方案
总体设计上使用双long的16进制字符串作为traceId,这和opentelemetry保持一致。
双long的共128位中,保证41位表示时间戳(可使用69.7年)、23位表示序列号(每毫秒800万事件),剩余的64位用于保证唯一。
具体方案有以下三种:
方案一
41位时间戳(毫秒)+ 23位序列号+ 64位伪随机long

方案二
41bit时间戳(毫秒)+ 23位(自增id)+ 32bit IPv4 + 32位伪随机int,,每5000个trace生成一次随机int

方案三
41bit时间戳(毫秒)+ 23位(自增id)+ 由128位IPv6通过异或位运算折叠得到的32位 + 32位伪随机int,每5000个trace生成一次随机int

方案二和方案三需要使用IP地址来得到32位,使用局域网地址的意义不大,如何获取公网ip地址是一个待解决的问题。
方案评估
由于获取公网IP需要额外的依赖,并且针对IPv4和IPv6需要不同处理,增加了复杂度,最终选定方案一。
TraceId传输方案
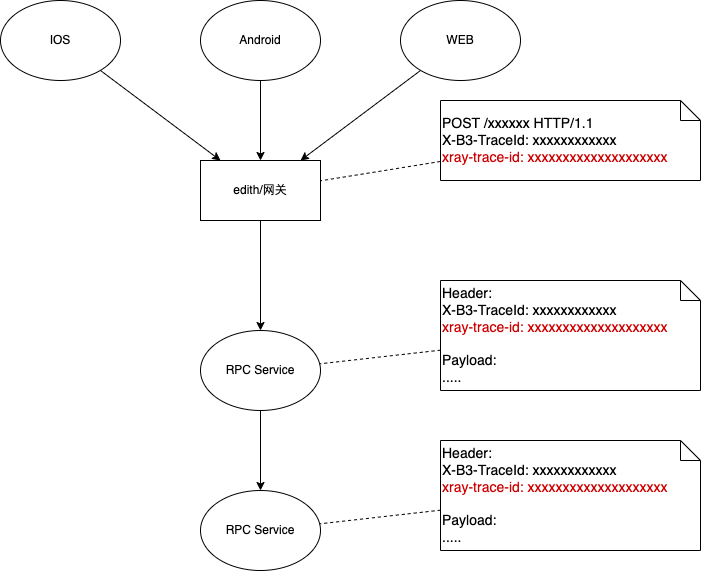
IOS/Android/WEB当前使用Zipkin (B3) HTTP header传递traceId,相关header为X-B3-TraceId.
为避免兼容性问题,老的header不改动,新增一个header:x-trace-id来传递新的traceId。
参考资料
3. UUID
4. UUIDv1⽣成