
为什么学习 rust?
- 高性能:Rust 速度惊人且内存利用率极高。由于没有运行时和垃圾回收,它能够胜任对性能要求特别高的服务,可以在嵌入式设备上运行,还能轻松和其他语言集成。
- 可靠性:Rust 丰富的类型系统和所有权模型保证了内存安全和线程安全,让您在编译期就能够消除各种各样的错误。
- 生产力:Rust 拥有出色的文档、友好的编译器和清晰的错误提示信息, 还集成了一流的工具——包管理器和构建工具, 智能地自动补全和类型检验的多编辑器支持, 以及自动格式化代码等等。
入门路径
rust 的网站这样描述自己:我们喜欢写 document。rust 确实提供了很多不错的文档(go 的文档也很好
- rust book 了解 rust 设计、语法
- rust-by-example Rust 设计和语法的更多例子
- rust book 中文版
- rust 标准库文档
- std::* modules
- Primitive types
- Standard macros
- The Rust Prelude
- tokio 文档
- async/await 原理
rust book是一定需要看的,可以看rust book 中文版。第一次看的时候看的英文版,今年看的是中文版,感觉翻译还不错。rust 标准库文档当成工具书吧,类似 java doc 的那种存在。现在的软件开发可以说一切都是基于网络,所以一个网络编程框架是肯定要学习的。tokio 是目前最火的网络编程框架吧。tokio 文档这个文档以一个简单 redis 的 client/server 实现为例子,逐渐深入地介绍 tokio。tokio 对自己的定位不是网络编程框架,而是异步运行时。
安装
Linux
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- --default-host x86_64-unknown-linux-gnu -y
MacOS
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh -s -- -y
WINDOWS
使用 rust-init 程序,需要额外下载 visual studio 2019 的安装器,并安装 visual c++ 生成工具、windows 10 sdk、英文语言包
设置代理
rustup 安装和更新使用中科大镜像:
export RUSTUP_DIST_SERVER=https://mirrors.ustc.edu.cn/rust-static
export RUSTUP_UPDATE_ROOT=https://mirrors.ustc.edu.cn/rust-static/rustup
## windows:
$ENV:RUSTUP_DIST_SERVER='https://mirrors.ustc.edu.cn/rust-static'
$ENV:RUSTUP_UPDATE_ROOT='https://mirrors.ustc.edu.cn/rust-static/rustup'
## 然后运行安装脚本/rustup-init.exe
Cargo 是 rust 的包管理工具,类似 java 的 maven,设置代理如下:
cat >> ~/.cargo/config <<\EOF
[http]
proxy = "127.0.0.1:3128"
[https]
proxy = "127.0.0.1:3128"
EOF
或者使用中科大镜像
cat >> ~/.cargo/config <<\EOF
[source.crates-io]
registry = "https://github.com/rust-lang/crates.io-index"
replace-with = 'ustc'
[source.ustc]
registry = "git://mirrors.ustc.edu.cn/crates.io-index"
EOF
卸载
rustup self uninstall
集成开发环境
我使用的是 Clion+rust 插件
其他开发环境有https://www.rust-lang.org/zh-CN/tools
除了 Jetbrains 官方的插件,rust-analyzer 使用更加广泛,支持 vscode 等 ide,同时也强烈推荐 vscode。
rust 基础——理解怎么做到内存安全的
内存安全是 rust 最重要的特点。为了实现这一点,rust 增加了很多限制,这些限制是 rust 与其他语言最大的不同,也是 rust 学习路径陡峭的根本原因。
变量是默认不可变的
let x = 5;
x = 6; //编译器此时报错
需要增加 mut:
let mut x = 5;
x = 6;
基础数据类型
- 整型
- 浮点型
- 布尔
- 字符型
- 元组
- 数组
以上类型的 size 都固定,可以放在栈上
所有权系统
所有权系统解决什么?rust 号称是内存安全的,其内存安全的保证机制其实就是通过一些规范将运行时内存安全问题变成编译期问题,在编译时就暴露这些问题。这些规范就是所有权系统。
栈上数据:压栈=申请空间,出栈=释放空间。而压栈出栈是自动的,所有不需要手动申请和释放。 堆上数据:C/C++需要手动申请和释放。java 使用 new 关键字,垃圾收集器负责回收不再使用的空间。在 rust 中,既不存在 GC,也不需要手动释放空间,原因就是所有权系统。
所有权规则的简单介绍:
- Rust 中的每一个值都有一个被称为其 所有者(owner)的变量。
- 值在任一时刻有且只有一个所有者。
- 当所有者(变量)离开作用域,这个值将被丢弃。
owner 可以简单理解为指向堆上数据的指针,指针是存放在栈上的。那么,所有权系统的思想就是“当指针离开作用域时,释放该指针指向的堆上空间”,简单来说就是堆上数据随栈上指针的出栈而释放,或者说堆内存受栈内存生命周期的控制。但是这件事没有这么简单,否则为什么 C 不去实现“当指针离开作用域时,释放该指针指向的堆上空间”。
在实现上,rust 提供了 Move、Copy、Drop、和生命周期注解参数。
在 C 中,经常讨论传参是值传递的还是引用传递的,java 中也有 java 只使用值传递的说法。在 rust 中没有值传递还是引用传递的说法,rust 说的是 Move 和 Copy。Move 通常用于堆上数据,是指不进行拷贝,直接把指针/引用传递过去,“所有权”也相应地移动到了目标作用域里——适用于堆上数据,因为堆上数据拷贝成本高,同时堆上数据需要进行释放。Copy 通常用于栈,主要用于基础数据类型(size 编译器确定,可以放在栈上的数据)。Move 和 Copy 其实是想保证规则“2. 值在任一时刻有且只有一个所有者”。
栈上的数据(Copy)是可以自动回收的。Move 语义保证堆上的数据只能有一个所有者,所有者负责回收资源。
对于 Move trait 的类型,可以使用借用,也可以使用
.clone深拷贝出一个对象,进行传参。但是深拷贝是开销很大的,也可以选择使用 Rc 智能指针包裹(见下文)。
那什么是 Drop 呢?回忆一下 java8 的 try-with-resource 语法:
try(InputStream in=new ByteArrayInputStream("aaaa".getBytes(StandardCharsets.UTF_8))){
// doSomeThing...
}catch (Throwable e){
e.printStackTrace();
}
try-with-resource 会自动帮我们在 finnal 语句中调用资源的 close 方法,实现资源的自动释放。Drop 的实现方式类似。被标记为 Drop 的类型,在离开作用域时编译器会“织入”drop 代码,以自动地释放空间。
到这里还没有介绍生命周期注解参数的作用,等到介绍“引用和借用”的时候再说生命周期注解参数解决的是什么问题。
Rc<>智能指针-用引用计数更加灵活的控制堆上数据的生命周期
先说下堆和栈上数据的区别:
- 栈上数据:大小在编译期固定,生命周期在编译器固定
- 堆上数据:大小和生命周期都不能在编译期固定。
而上面的所有权体系的基础是,堆上数据随栈上指针的出栈而释放,也就是堆上数据的生命周期由他的指针的生命周期决定。但是如果多个指针都用到同一个堆上数据,只要有一个指针没有消亡,堆上数据就不能释放怎么办呢?这时候就要引用计数出马了,就是 Rc<>智能指针。
我们先看 Rc。对某个数据结构 T,我们可以创建引用计数 Rc,使其有多个所有者。Rc 会把对应的数据结构创建在堆上,我们在第二讲谈到过,堆是唯一可以让动态创建的数据被到处使用的内存。
use std::rc::Rc;
fn main() {
let a = Rc::new(1);
}
之后,如果想对数据创建更多的所有者,我们可以通过 clone() 来完成。对一个 Rc 结构进行 clone(),不会将其内部的数据复制,只会增加引用计数。而当一个 Rc 结构离开作用域被 drop() 时,也只会减少其引用计数,直到引用计数为零,才会真正清除对应的内存。
use std::rc::Rc;
fn main() {
let a = Rc::new(1);
let b = a.clone();
let c = a.clone();
}
上面的代码我们创建了三个 Rc,分别是 a、b 和 c。它们共同指向堆上相同的数据,也就是说,堆上的数据有了三个共享的所有者。在这段代码结束时,c 先 drop,引用计数变成 2,然后 b drop、a drop,引用计数归零,堆上内存被释放。
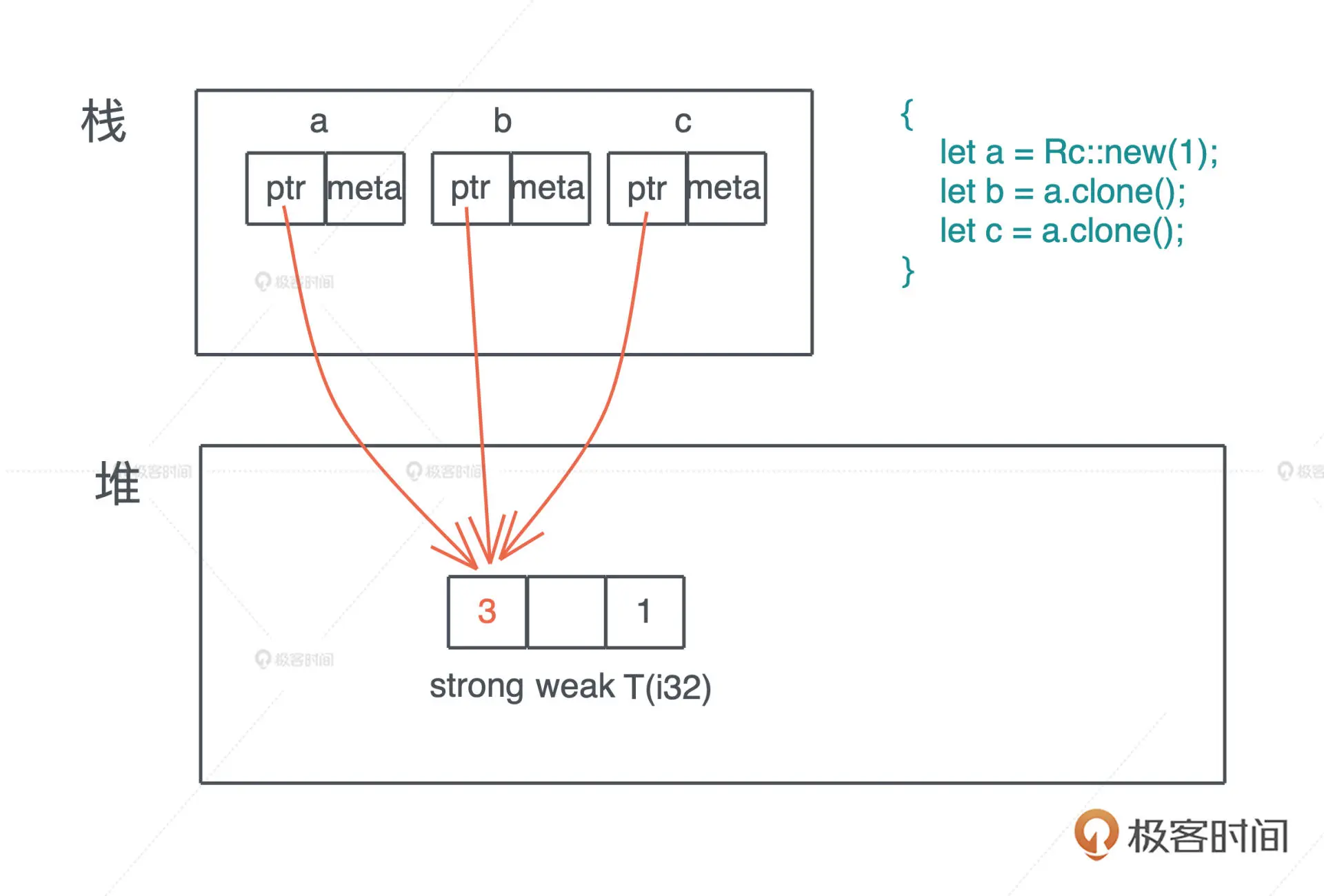
你也许会有疑问:为什么我们生成了对同一块内存的多个所有者,但是,编译器不抱怨所有权冲突呢?
仔细看这段代码:首先 a 是 Rc::new(1) 的所有者,这毋庸置疑;然后 b 和 c 都调用了 a.clone(),分别得到了一个新的 Rc,所以从编译器的角度,abc 都各自拥有一个 Rc。如果文字你觉得稍微有点绕,看看 Rc 的 clone() 函数的实现,就很清楚了(源代码):
fn clone(&self) -> Rc<T> {
// 增加引用计数
self.inner().inc_strong();
// 通过 self.ptr 生成一个新的 Rc 结构
Self::from_inner(self.ptr)
}
所以,Rc 的 clone() 正如我们刚才说的,不复制实际的数据,只是一个引用计数的增加。
你可能继续会疑惑:Rc 是怎么产生在堆上的?并且为什么这段堆内存不受栈内存生命周期的控制呢?
Box::leak() 机制
上一讲我们讲到,在所有权模型下,堆内存的生命周期,和创建它的栈内存的生命周期保持一致。所以 Rc 的实现似乎与此格格不入。的确,如果完全按照上一讲的单一所有权模型,Rust 是无法处理 Rc 这样的引用计数的。Rust 必须提供一种机制,让代码可以像 C/C++ 那样,创建不受栈内存控制的堆内存,从而绕过编译时的所有权规则。Rust 提供的方式是 Box::leak()。
Box 是 Rust 下的智能指针,它可以强制把任何数据结构创建在堆上,然后在栈上放一个指针指向这个数据结构,但此时堆内存的生命周期仍然是受控的,跟栈上的指针一致。我们后续讲到智能指针时会详细介绍 Box。Box::leak() ,顾名思义,它创建的对象,从堆内存上泄漏出去,不受栈内存控制,是一个自由的、生命周期可以大到和整个进程的生命周期一致的对象。
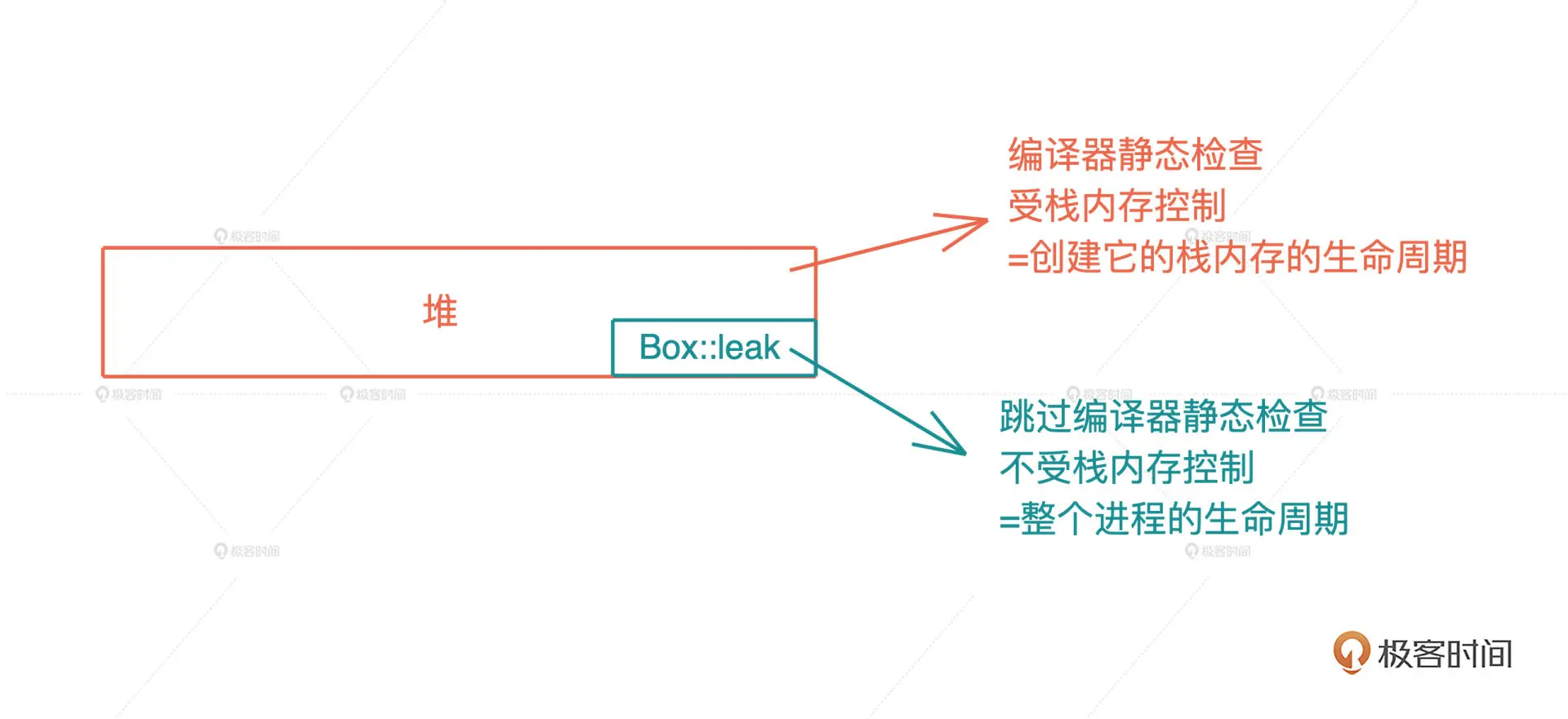
所以我们相当于主动撕开了一个口子,允许内存泄漏。注意,在 C/C++ 下,其实你通过 malloc 分配的每一片堆内存,都类似 Rust 下的 Box::leak()。我很喜欢 Rust 这样的设计,它符合最小权限原则(Principle of least privilege),最大程度帮助开发者撰写安全的代码。
有了 Box::leak(),我们就可以跳出 Rust 编译器的静态检查,保证 Rc 指向的堆内存,有最大的生命周期,然后我们再通过引用计数,在合适的时机,结束这段内存的生命周期。如果你对此感兴趣,可以看 Rc::new() 的源码。
搞明白了 Rc,我们就进一步理解 Rust 是如何进行所有权的静态检查和动态检查了:
- 静态检查,靠编译器保证代码符合所有权规则;
- 动态检查,通过 Box::leak 让堆内存拥有不受限的生命周期,然后在运行过程中,通过对引用计数的检查,保证这样的堆内存最终会得到释放。
结合 Move、Copy、Drop 和 Rc 引用计数,我们发现,Rust 的创造者们,重新审视了堆内存的生命周期,发现大部分堆内存的需求在于动态大小,小部分需求是更长的生命周期。所以它默认将堆内存的生命周期和使用它的栈内存的生命周期绑在一起,并留了个小口子 leaked 机制,让堆内存在需要的时候,可以有超出帧存活期的生命周期。我们看下图的对比总结:
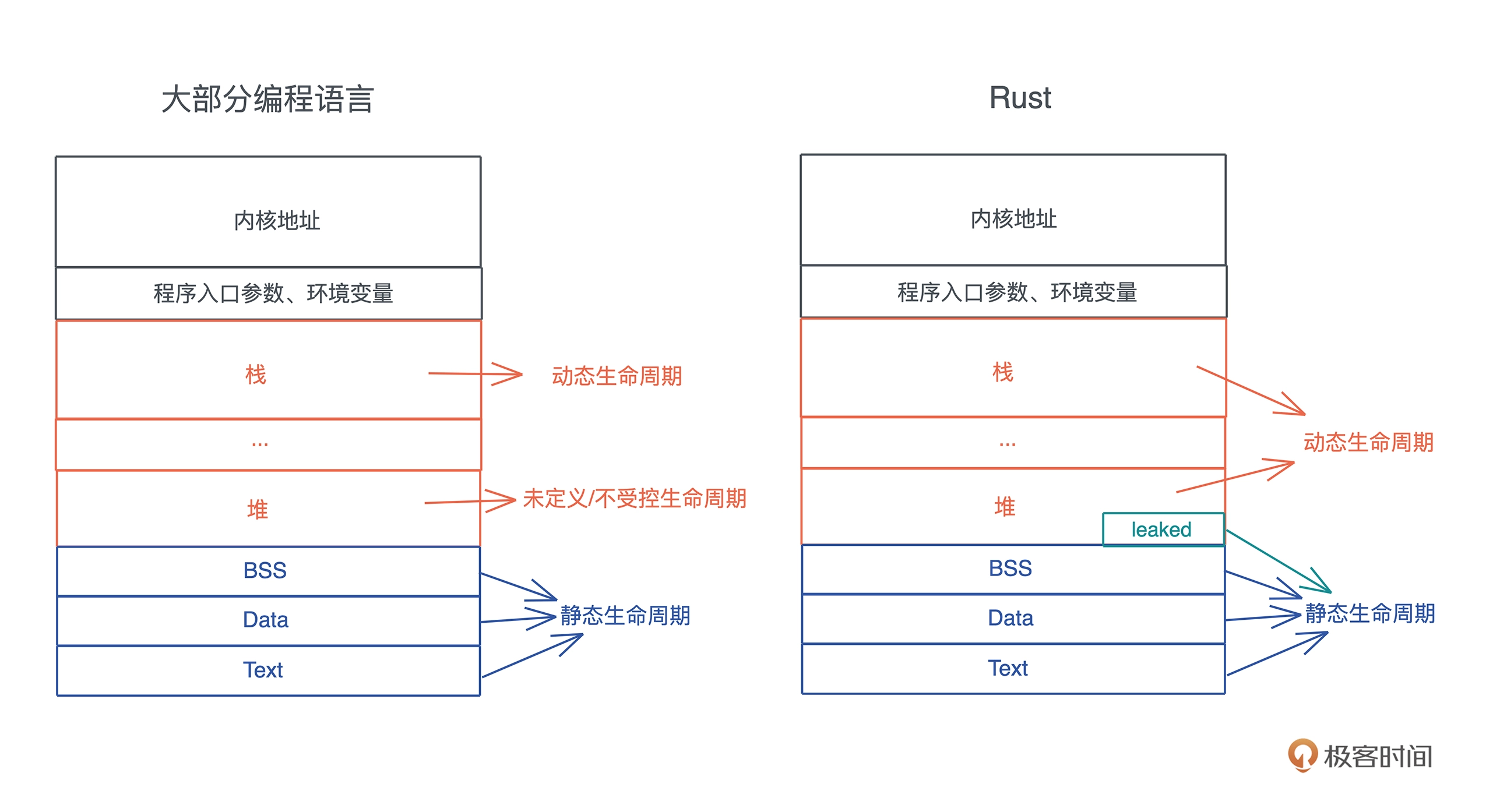
- 栈上数据随出栈释放
- 大部份堆上的数据随栈上的所有者指针释放
- 少部分需要存活的更久的堆上数据,先 leak 成为静态生命周期的数据,再根据引用计数降低至 0 时释放。
引用和借用
上面我们介绍了所有权系统,堆上数据一般都是 Move trait 的,传递这些参数将会移动所有权到新的作用域中。问题来了:
fn main(){
let s = String::from("string");
useString(s);
println!{"{}",s}; //这里将报错
}
fn useString(s: String){
// s的所有权移动到这里
}
上面的代码报错是符合所有权系统的原则的。如果我们还想使用s,需要改成这样:
fn main(){
let s = String::from("string");
let s=useString(s);
println!{"{}",s};
}
fn useString(s: String) -> String{
s // = return s;
}
也即是再把 s 的所有权返回回去。这种代码很傻逼,于是借用的概念就出来了,用引用(&)来表达借用。
借用允许不获取所有权的情况下使用变量。我们可以这样改造代码:
fn main() {
let s = String::from("string");
useString(&s);
println! {"use {} again", s};
}
fn useString(s: &String) {
println! {"use {}", s};
}
但是借用又有一些问题需要解决:前面讲了 rust 是默认不可变的,引用也有可变的和不可变的,分别为& mut和&,这里就有两个规则:
- 在任意给定时间,要么 只能有一个可变引用,要么 只能有多个不可变引用。
- 引用必须总是有效的。
为什么“引用必须总是有效的”?因为引用所指向的数据如果已经被释放,那么就会导致一些错误,这就是“悬垂指针”。“悬垂指针”也是内存安全问题的一种,rust 也致力于在编译器暴露这种问题,他的解决方案就是“生命周期注解参数”:
fn main() {
let s = String::from("string");
let sl = String::from("longer string");
println! {"longer is {}", longest(&s,&sl)};
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
'a表示一种生命周期,还可以有'b,'c来表示不同的生命周期。被相同生命周期注解的参数拥有相同的生命周期。
rust 的编译器能自动地判断一些引用的生命周期,所以不是所有情况都需要显式使用生命周期注解参数。不要畏惧生命周期注解参数,你只需要在编译器提醒你的时候加上他们。生命周期注解参数不会改变生命周期。
‘staitic 作为 trait bound
rust-by-example中说这意味着所有权被 move 到这个 scope 里。也就是说,不能传引用

Pin 和 Unpin
Pin<P<T>> 是常见的结构,其中 P 是 T 的指针,比如 Pin<&String> 或 Pin<Box<T>>。Pin 的主要目的是确保 T:!Unpin(没有实现 Unpin) 在内存中的位置不会改变,这在自引用结构中非常重要,异步 rust 的 async/await 基于的 generaotr、状态机就包含子引用结构。
自引用结构:
// 这是一个自引用结构(self-referential struct)
struct SelfReferential {
data: String,
pointer: *const String, // 指向自己的data字段
}
impl SelfReferential {
fn new(text: &str) -> Self {
let mut s = SelfReferential {
data: String::from(text),
pointer: std::ptr::null(),
};
// 让pointer指向data
s.pointer = &s.data as *const String;
s
}
fn get_data(&self) -> &str {
unsafe { &*self.pointer }
}
}
fn demonstrate_problem() {
let mut s1 = SelfReferential::new("hello");
println!("{}", s1.get_data()); // OK: "hello"
// 问题:移动后指针失效!
let s2 = s1; // s1被移动到s2
// s2.pointer仍然指向s1的旧地址!
// println!("{}", s2.get_data()); // 未定义行为!悬垂指针!
}
核心问题:当结构体被移动(move)时,内部的指针不会自动更新,导致悬垂指针。
Rust 有两种方式移动内存:
- 变量声明
fn main() {
let mut s1 = String::from("Hello");
let s2 = s1; // s1的所有权转移给了s2,这里发生了move
// let s3 = s1; // s1的所有权以及转移走了,不能再move,否则会报错:error[E0382]: use of moved value: `s1`
}
- 使用
std::mem::swap等api 传入可变引用
fn main() {
let mut x = String::from("xxx");
let mut y = String::from("yyy");
std::mem::swap(&mut x, &mut y);
assert_eq!("yyy", &x);
assert_eq!("xxx", &y);
}
第二种方式说明,暴露了可变引用就可能导致内存位置改变。所以 Pin 的作用就是避免暴露 T 的可变引用。但是又给 T: Unpin 的类型放开了这个限制。
Unpin: 即使被pin住,也可以安全的被移动。从下面的代码看就是,能从Pin中拿到可变引用
于是我们来到 Pin 的标准库定义:
/// A pinned pointer.
///
/// This is a wrapper around a kind of pointer which makes that pointer "pin" its
/// value in place, preventing the value referenced by that pointer from being moved
/// unless it implements [`Unpin`].
#[stable(feature = "pin", since = "1.33.0")]
#[lang = "pin"]
#[fundamental]
#[repr(transparent)]
#[derive(Copy, Clone)]
pub struct Pin<P> {
pointer: P,
}
// 如果T: !Unpin,那么只能拿到不可变引用
#[stable(feature = "pin", since = "1.33.0")]
impl<P: Deref> Deref for Pin<P> {
type Target = P::Target;
fn deref(&self) -> &P::Target {
Pin::get_ref(Pin::as_ref(self))
}
}
// 这里给 T: Unpin 的类型放开了 Pin 的限制,因为可以拿到可变引用,然后用在std::mem::swap 中
#[stable(feature = "pin", since = "1.33.0")]
impl<P: DerefMut<Target: Unpin>> DerefMut for Pin<P> {
fn deref_mut(&mut self) -> &mut P::Target {
Pin::get_mut(Pin::as_mut(self))
}
}
静态链接可执行文件
链接 Linkage 更多的是编译器的概念而不是语言的概念,Rust 直接使用了 gcc 或 msvc 等现成编译器的链接器。因此我们先拿 gcc 的命令来解释下静态链接:
gcc -static -o main main.c -I/path/to/include -L/path/to/library -lexample
这里的命令选项解释如下:
-static是一个 GCC 链接选项,用于指示链接器尽可能使用静态库来构建程序。当使用这个选项时,链接器会尝试将所有程序使用的库以静态库的形式链接进可执行文件,包括 C 标准库(libc)、数学库(libm)等通用库。-o main指定输出的可执行文件名为main。main.c是包含main函数的源文件。-I/path/to/include指定额外的头文件目录。-L/path/to/library添加静态库的搜索路径。如果静态库位于标准库路径,这个选项可以省略。-lexample指定链接库libexample.a。GCC 会自动在给定的路径中搜索以lib开头且以.a结尾的文件,所以只需写出example。
参考Rust Linkage: Static and dynamic C runtimes,Rust 的 toolchain 支持动态和静态两种链接方式,可以指定crt-static target feature 来手动配置。大部份 toolchain 默认是动态链接的,musl 的 toolchain 则默认是静态链接。下面就以 x86_64-unknown-linux-gnu 和 x86_64-unknown-linux-musl 两种 linux 上常见的 toolchain 为例介绍如何进行静态链接,并介绍使用 build.rs 让部分库使用静态链接
x86_64-unknown-linux-gnu
参考Linkage - The Rust Reference
RUSTFLAGS="-C target-feature=+crt-static" cargo build --release --target x86_64-unknown-linux-gnu
注意:
--target x86_64-unknown-linux-gnu不能省略- 可执行文件在
/target/x86_64-unknown-linux-gnu/release/
如果报错:
/usr/bin/ld: cannot find -lm
/usr/bin/ld: cannot find -lc
说明系统上缺少了 C 标准库(libc)、数学库(libm)等通用库,安装即可。
以我的 redhat9 开发机为例,缺失的是 glibc-static
# search from https://pkgs.org/search/?q=libc.a
# centos 9
dnf --enablerepo=crb install glibc-static
# redhat9
subscription-manager repos --enable codeready-builder-for-rhel-9-x86_64-rpms # https://access.redhat.com/articles/4348511
yum install -y glibc-static # yum whatprovides "*/libc.a"
以 ubuntu 为例,缺失的是 libc6-dev
apt install -y libc6-dev
$ apt update && apt-get install -y apt-file && apt-file update && apt-file search libc.a | grep "libc6-dev:"
libc6-dev: /usr/lib/x86_64-linux-gnu/libc.a
$ apt-file search libm.a | grep "libc6-dev:"
libc6-dev: /usr/lib/x86_64-linux-gnu/libm.a
x86_64-unknown-linux-musl
因为 musl 默认使用静态链接,所以只需要编译安装 musl 和增加 musl toolchain 即可,不需要增加 RUSTFLAGS。建议是编译安装 musl 而不是使用发行版提供的 musl-dev,因为发行版提供的 musl-dev 版本可能比较老,还是用 32 位的类型,可能导致编译不通过。参考musl: Change time_t definition on 32-bit targets according to “time64”
musl 1.2 is now available and changes time_t for 32-bit archs to a 64-bit type。 PS: 具体而言,好像是从 1.2.4 开始支持 64 位的 time_t
- 安装 musl
cd /var/
version=1.2.5
curl -SsLf http://musl.libc.org/releases/musl-${version}.tar.gz -o musl-${version}.tar.gz
tar -zxf musl-${version}.tar.gz
cd musl-${version}
./configure > /dev/null
make -j 2 > /dev/null
make install > /dev/null
ln -fs /usr/local/musl/bin/musl-gcc /usr/bin/musl-gcc
- 安装 musl toolchain
rustup target add x86_64-unknown-linux-musl
- 使用 musl toolchain 编译
# debug, 可执行文件在target/x86_64-unknown-linux-musl/debug/
cargo build --target x86_64-unknown-linux-musl
# release,可执行文件在target/x86_64-unknown-linux-musl/release/
cargo build --release --target x86_64-unknown-linux-musl
使用 build.rs 指定静态链接部分库
当然,除了全局静态链接,也可以在 build.rs 中指定仅仅静态链接某些库,可以参考 deeplflow agent 的 build.rs,例如:
println!("cargo:rustc-link-lib=static=c");
println!("cargo:rustc-link-lib=static=elf");
println!("cargo:rustc-link-lib=static=m");
println!("cargo:rustc-link-lib=static=z");
也可以在 build.rs 中设置库的搜索路径,例如:
if target_env.as_str() == "musl" {
#[cfg(target_arch = "x86_64")]
println!("cargo:rustc-link-search=native=/usr/x86_64-linux-musl/lib64");
#[cfg(target_arch = "aarch64")]
println!("cargo:rustc-link-search=native=/usr/aarch64-linux-musl/lib64");
}
println!("cargo:rustc-link-search=native=/usr/lib");
println!("cargo:rustc-link-search=native=/usr/lib64");
其他关于 build.rs 可以参考The build script
静态链接部分库也可以成为局部静态链接,举个例子介绍 gcc 怎么做局部静态链接,rustc 可以举一反三:
gcc -o myprogram myprogram.c -Wl,-Bstatic -lfoo -lbar -Wl,-Bdynamic -lbaz
这个命令做了以下几点:
-Wl,前缀是用来告诉 GCC 将后面的选项传递给链接器。-Wl,-Bstatic使链接器进入静态链接模式。-lfoo -lbar指定静态链接libfoo和libbar。-Wl,-Bdynamic切换回动态链接模式。-lbaz使用动态链接方式链接libbaz。
注意事项
- 确保在命令中正确地放置
-Wl,-Bstatic和-Wl,-Bdynamic。错误的顺序可能导致不期望的链接行为。 - 确保系统中有对应库的静态版本(通常是
.a文件)和动态版本(如.so文件)。 - 在某些系统中,静态链接特定的系统库可能与系统策略或安全设置冲突,可能需要额外的配置或权限。
通过这种方式,你可以在保持应用部分依赖动态链接的灵活性和系统兼容性的同时,对关键或特定的依赖库使用静态链接,以提高应用的自包含性和部署的便利性。
上面谈到的都是针对 C Runtime 的静态链接。如果涉及到一些非通用的 c 库,例如 libbpf-rs 依赖 libelf 和 zlib,这种还是要单独处理的,这种 crate 一般会有 xxxx-sys 子 crate,用于编译 c 库,也会提供 vendored 特性来开启静态链接,例如 libbpf-sys 的 build.rs。
一些备忘
- rust-by-example | static_lifetime of trait-bound
- the book | Smart Pointers 在 Rust 中,凡是需要做资源回收的数据结构,且实现了 Deref/DerefMut/Drop,都是智能指针
- rust-by-example | 宏编程
- std | pin module
- the book | Generic Types, Traits, and Lifetimes
- the book | “?”简化错误传播
- rust-by-example | newType 类型驱动编程
- reference | 临时结果的生命周期
- 极客时间 | 38 | 异步处理:Future 是什么?它和 async/await 是什么关系?
- 非常重要,反复观看极客时间 | 39 | 异步处理:async/await 内部是怎么实现的?
- 极客时间 | 19 | 闭包:FnOnce、FnMut 和 Fn,为什么有这么多类型?
- 极客时间 | 13 | 类型系统:如何使用 trait 来定义接口?
- 极客时间 | 14 | 类型系统:有哪些必须掌握的 trait?
- 极客时间 | 15 | 数据结构:这些浓眉大眼的结构竟然都是智能指针?
- 重点是在 async read 中拆包解包极客时间 | 36 | 阶段实操(4):构建一个简单的 KV server-网络处理
Rust 博客
- Return type notation MVP: Call for testing! 解决
RPITIT+Send的问题 - Changes to
impl Traitin Rust 2024 “use bound”: impl Trait + use<‘x, T> - 于 Rust 1.75 稳定的 RPITIT 与 AFIT
- 非常重要,反复观看Rust 的 Pin 与 Unpin
- 非常重要,反复观看Rust Pin 进阶