
ClickHouse是一个列式数据库管理系统,可用于联机分析(OLAP)。ClickHouse最常用的表引擎是MergeTree,下面主要围绕该种表引擎展开。
OLAP场景适合使用列式存储
列式存储的特点
- 同一列的数据存储在一起。
- 局部性:。同一列的数据存储在一起,满足局部性,适合用于聚合操作。例如select sum(column) from table。
- 同一列的数据是相同类型,可以选取适合的压缩算法,以得到较高的压缩率,从而减少磁盘的占用,以及内存缓存更多的数据。例如数值类型可以使用delta-of-delta压缩。
- 压缩意味着数据以块的形式存储。
- 仅适合增加数据,更新不能原地更新,只能追加变更记录。
- 适合使用LSM的数据结构
OLAP的特点
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
MergeTree
新数据插入到表中时,这些数据会存储为按主键排序的新片段(块)。插入后 10-15 分钟,同一分区的各个片段会合并为一整个片段。
- 以块的形式存储
- 主键有序
- 合并
LSM Tree
MergeTree类似于LSM(Log-Structured-Merge-Tree)。
以下引用自LSM树详解
LSM树的核心特点是利用顺序写来提高写性能,但因为分层(此处分层是指的分为内存和文件两部分)的设计会稍微降低读性能,但是通过牺牲小部分读性能换来高性能写,使得LSM树成为非常流行的存储结构。
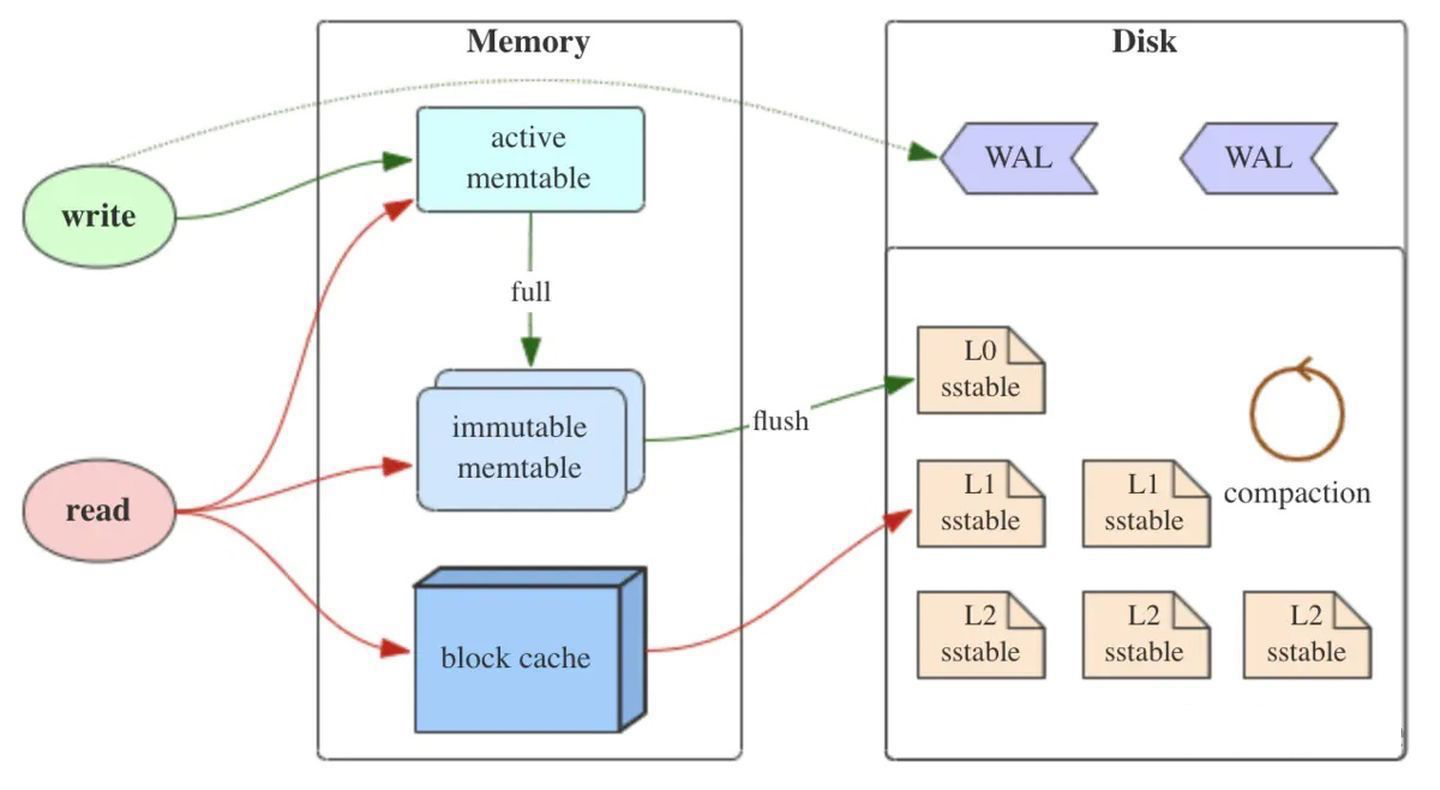
如上图所示,LSM树有以下三个重要组成部分:
1) MemTable
MemTable是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据,LSM树对于具体如何组织有序地组织数据并没有明确的数据结构定义,例如Hbase使跳跃表来保证内存中key的有序。
因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过WAL(Write-ahead logging,预写式日志)的方式来保证数据的可靠性。
2) Immutable MemTable
当 MemTable达到一定大小后,会转化成Immutable MemTable。Immutable MemTable是将转MemTable变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。
3) SSTable(Sorted String Table)

有序键值对集合,是LSM树组在磁盘中的数据结构。为了加快SSTable的读取,可以通过建立key的索引以及布隆过滤器来加快key的查找。
这里需要关注一个重点,LSM树(Log-Structured-Merge-Tree)正如它的名字一样,LSM树会将所有的数据插入、修改、删除等操作记录(注意是操作记录)保存在内存之中,当此类操作达到一定的数据量后,再批量地顺序写入到磁盘当中。这与B+树不同,B+树数据的更新会直接在原数据所在处修改对应的值,但是LSM数的数据更新是日志式的,当一条数据更新是直接append一条更新记录完成的。这样设计的目的就是为了顺序写,不断地将Immutable MemTable flush到持久化存储即可,而不用去修改之前的SSTable中的key,保证了顺序写。
因此当MemTable达到一定大小flush到持久化存储变成SSTable后,在不同的SSTable中,可能存在相同Key的记录,当然最新的那条记录才是准确的。这样设计的虽然大大提高了写性能,但同时也会带来一些问题:
1)冗余存储,对于某个key,实际上除了最新的那条记录外,其他的记录都是冗余无用的,但是仍然占用了存储空间。因此需要进行Compact操作(合并多个SSTable)来清除冗余的记录。
2)读取时需要从最新的倒着查询,直到找到某个key的记录。最坏情况需要查询完所有的SSTable,这里可以通过前面提到的索引/布隆过滤器来优化查找速度。
MergeTree相关概念
- paritition: 可以按照任意标准进行分区,例如按月、按日或按事件类型。
- 数据片段(dataPart):一段有序的数据
- 主键(order by):不同于mysql,这里的主键仅指按照什么规则进行排序。
- 颗粒(granular):颗粒的大小=稀疏索引的粒度。通过index_granularity控制一个粒度所包含的行数。
- 跳数索引:用于一次性越过多个颗粒。主键和颗粒粒度决定了每隔多少行标记一个offset。如果很多个颗粒的主键都是一样的,就可以考虑通过跳数索引来一次行越过多个颗粒(另一种思路是在主键中加入新的列)。跳数索引有minmax(类似主键索引)、set、各种布隆过滤器。
分区键和主键的作用:ClickHouse 会依据主键索引剪掉不符合的数据,依据按月分区的分区键剪掉那些不包含符合数据的分区
MergeTree存储结构
ClickHouse内核分析-MergeTree的存储结构和查询加速
表的数据存储在$path/data/$database/$table目录下,该目录下的子目录格式为:
$partitionId_$minBlock_$maxBlock_$level
并且,一个partition是分为多个目录的,举个实际的例子如下:
ls |grep 8f244a4f142a2f3c5ea8da2fbc25405b
8f244a4f142a2f3c5ea8da2fbc25405b_0_106_20
8f244a4f142a2f3c5ea8da2fbc25405b_107_112_1
8f244a4f142a2f3c5ea8da2fbc25405b_107_135_2
8f244a4f142a2f3c5ea8da2fbc25405b_113_118_1
8f244a4f142a2f3c5ea8da2fbc25405b_119_119_0
8f244a4f142a2f3c5ea8da2fbc25405b_119_124_1
8f244a4f142a2f3c5ea8da2fbc25405b_120_120_0
可以看到第一个文件夹的存储了0到106的block,并且经过了20次compaction。不同的partition不会做compaction到一起。我们每次insert都会生成一个Data part,而这个data part就是一个level为0的目录。
Data Part目录下的核心文件有
| 文件名 | 描述 | 作用 |
|---|---|---|
| primary.idx | 索引文件 | 用于存放稀疏索引 |
| [Column].mrk2 | 标记文件 | 保存了bin文件中数据的偏移信息,用于建立primary.idx和[Column].bin文件之间的映射 |
| [Column].bin | 数据文件 | 存储数据,默认使用lz4压缩存储 |
以下面的DDL为例:
- partition by 日期、小时、地域
- 主键是action_id、scene_id…
- 有avatar_id上的minmax索引
CREATE TABLE user_action_log (
`time` DateTime DEFAULT CAST('1970-01-01 08:00:00', 'DateTime') COMMENT '日志时间',
`action_id` UInt16 DEFAULT CAST(0, 'UInt16') COMMENT '日志行为类型id',
`action_name` String DEFAULT '' COMMENT '日志行为类型名',
`region_name` String DEFAULT '' COMMENT '区服名称',
`uid` UInt64 DEFAULT CAST(0, 'UInt64') COMMENT '用户id',
`level` UInt32 DEFAULT CAST(0, 'UInt32') COMMENT '当前等级',
`trans_no` String DEFAULT '' COMMENT '事务流水号',
`ext_head` String DEFAULT '' COMMENT '扩展日志head',
`avatar_id` UInt32 DEFAULT CAST(0, 'UInt32') COMMENT '角色id',
`scene_id` UInt32 DEFAULT CAST(0, 'UInt32') COMMENT '场景id',
`time_ts` UInt64 DEFAULT CAST(0, 'UInt64') COMMENT '秒单位时间戳',
index avatar_id_minmax (avatar_id) type minmax granularity 3
) ENGINE = MergeTree()
PARTITION BY (toYYYYMMDD(time), toHour(time), region_name)
ORDER BY (action_id, scene_id, time_ts, level, uid)
PRIMARY KEY (action_id, scene_id, time_ts, level);
这张表的逻辑存储如下,主要展示partition、data part和Merge Tree的分层结构
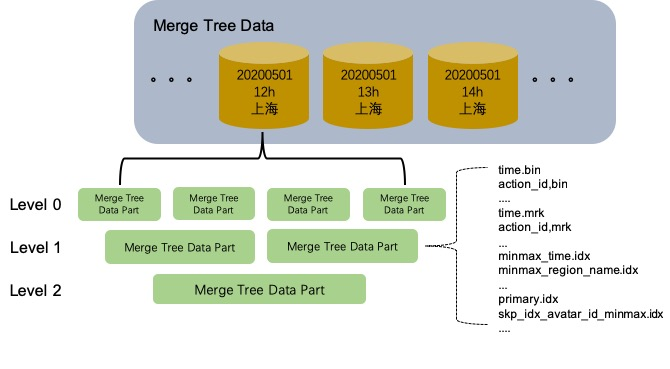
可以看到idx、mrk2、bin文件都是data part级别的,我们在看下这些文件是如何存储data part的。
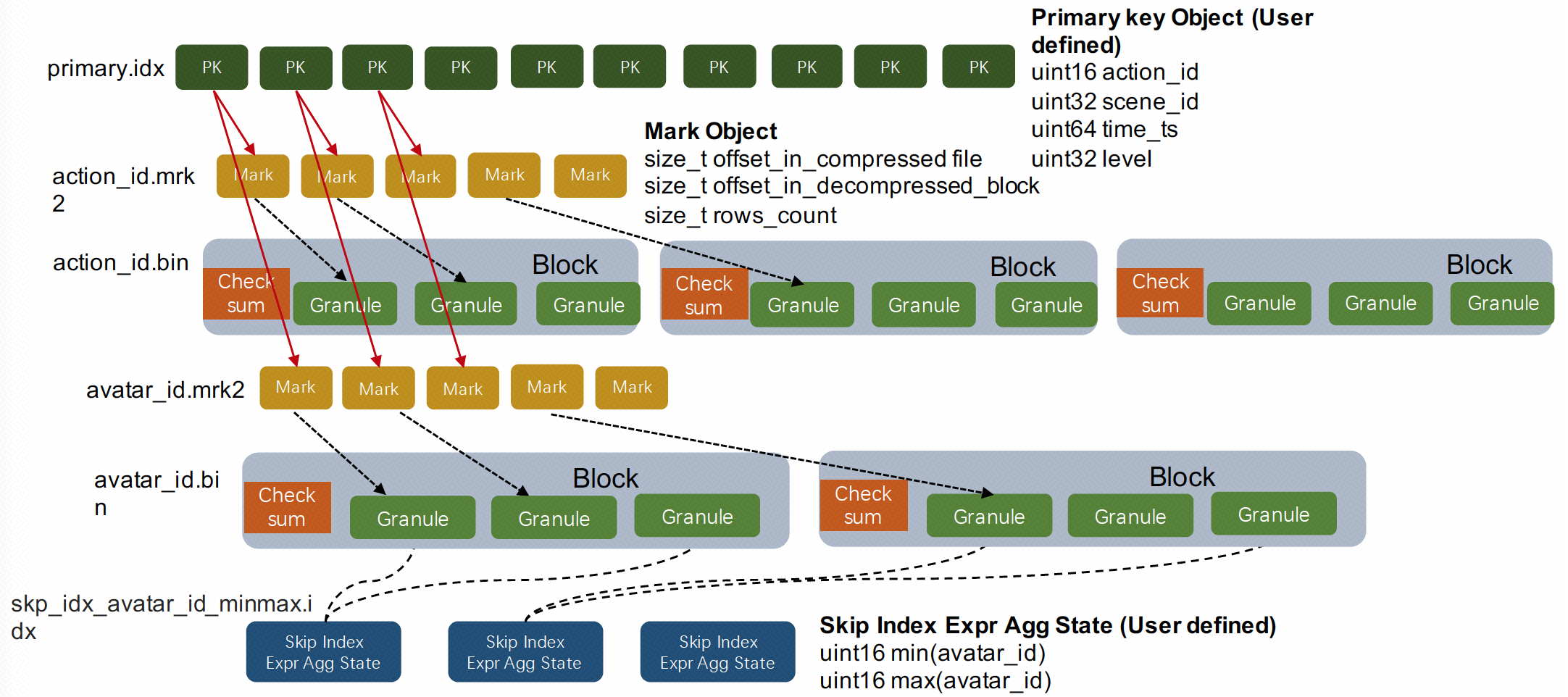
- primary.idx即稀疏索引,每个颗粒的第一个object会存储在primary.idx中(有多少颗粒,就有多少稀疏索引
- [column].mrk2是一个kv结构,存储primary.idx中的object在bin中的offset
- [column].bin数据文件
- 存储压缩后的数据
- 以块的形式存储,多个颗粒形成一个block并进行压缩
针对这种存储结构,clikhouse查询时,会先通过primary.idx找到大致的范围,再通过mrk2找到bin文件中位置,最后解压block得到数据
Projection
Projection广泛用于预聚合的场景。最大的优势是两点:
- 预聚合,使用空间换时间。写入时就进行聚合,查询时不需要再从明细数据计算出聚合结果。
- Projection是表中表的结构,原始表和Projection可以有不同的主键(不同的排序索引),从而实现多序,满足不同的查询需求。
详细解释下第二点:原始表video_log的排序索引是 (user_id, device_id)。我们知道where一定要包含排序索引的一部份才能使用到ck的稀疏索引的优势。

下面增加一个group by hour domain的Projection:
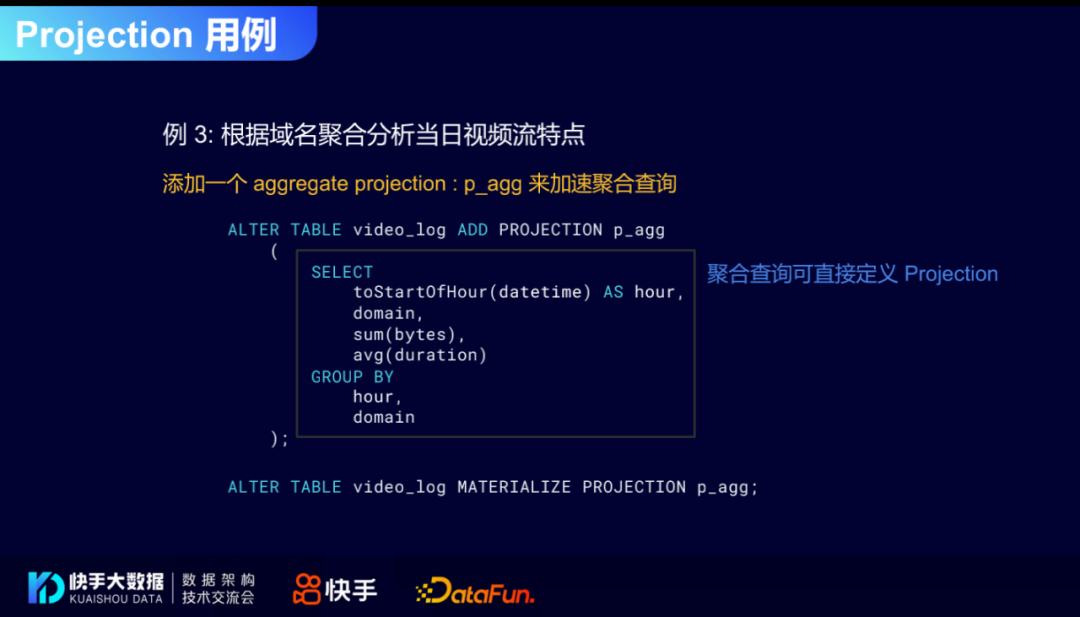
此时,Projection表的主键就是 (hour domain),此时where条件里就可以高效使用hour和domain了。
Projection的存储结构如下:重点是共享源Part的Partition,有自己的新主键(新排序索引)。

向量引擎
通过SIMD(Single Instruction Multiple Data)加速操作,ClickHouse使用SSE 4.2指令集。关于SIMD可见向量化并行(vectorization)
低基数类型
Set set=new HashSet<>(list)
考虑从list生成set,如果list不断膨胀,膨胀到非常大,最后生成的set的大小仍然比较小,则这个数据集就是低基数的。用sql描述就是:
select distinct column的结果比较小
低基数类型实际是使用字典索引。把遇到的元素都加入到字典中,每个元素一个index。然后用index代替元素本身,从而缩减存储和查询成本。
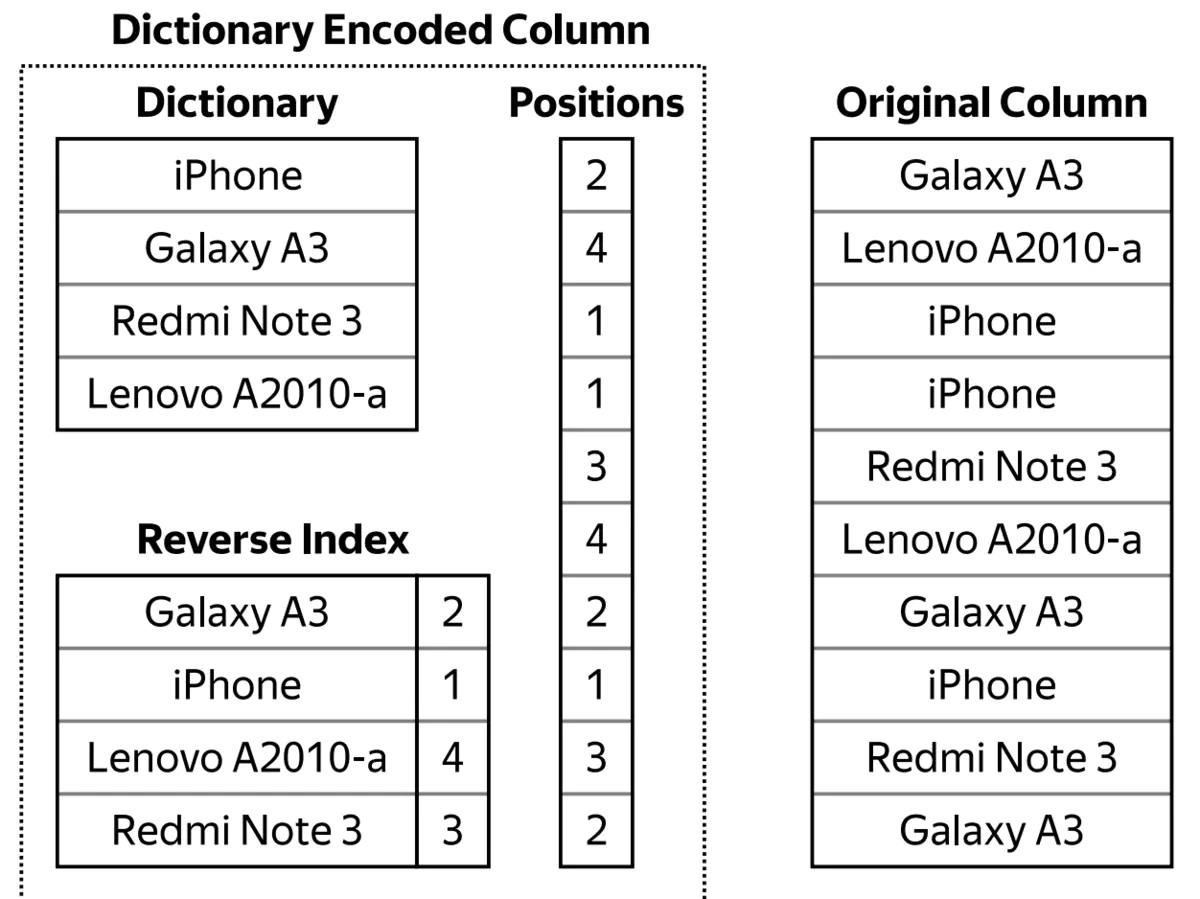
相对于低基数,高基数问题是监控场景下的常见问题:
高基数(High-Cardinality)的定义为在一个数据列中的数据基本上不重复,或者说重复率非常低。邮件地址,用户名等都可以被认为是高基数数据。
每一条数据称为一个样本(sample),由以下三部分组成:
- 指标/时间线(time-series):metricName + tagValues
- 时间戳(timestamp):一个精确到毫秒的时间戳;
- 样本值(value):表示当前样本的值。
比如随着时间流逝,云原生场景下 tag 出现 pod/container ID之类,也有些 tag 出现 userId,甚至有些 tag 是 url,而这些 tag 组合时,时间线膨胀得非常厉害。
分布式
- 分片(shard):创建分布式表
- 拷贝(replicate):创建ReplicatedMergeTree
- 使用zookeeper进行分布式协作
sharding规则在config.xml的remote_servers中,也可以在metrika.xml中配置,三分片两副本配置的例子如下:
<clickhouse_remote_servers>
<cluster>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>host1</host>
<port>9000</port>
<user>xxxx</user>
<password>xxxx</password>
</replica>
<replica>
<host>host2</host>
<port>9000</port>
<user>xxxx</user>
<password>xxxx</password>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>host3</host>
<port>9000</port>
<user>xxxx</user>
<password>xxxx</password>
</replica>
<replica>
<host>host4</host>
<port>9000</port>
<user>xxxx</user>
<password>xxxx</password>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>host5</host>
<port>9000</port>
<user>xxxx</user>
<password>xxxx</password>
</replica>
<replica>
<host>host6</host>
<port>9000</port>
<user>xxxx</user>
<password>xxxx</password>
</replica>
</shard>
</cluster>
</clickhouse_remote_servers>
为了防止生成过多part,采用写本地表、查分布式表的方式。
为了方式生成过多part,采取大批量的写入,采用10000以上的批次
Clickhouse与ES对比
-
ClickHouse写入吞吐量大,单服务器日志写入量在50MB到200MB/s,每秒写入超过60w记录数,是ES的5倍以上。在ES中比较常见的写Rejected导致数据丢失、写入延迟等问题,在ClickHouse中不容易发生。
-
查询速度快,官方宣称数据在pagecache中,单服务器查询速率大约在2-30GB/s;没在pagecache的情况下,查询速度取决于磁盘的读取速率和数据的压缩率。经测试ClickHouse的查询速度比ES快5-30倍以上。
-
ClickHouse比ES服务器成本更低。一方面ClickHouse的数据压缩比比ES高,相同数据占用的磁盘空间只有ES的1/3到1/30,节省了磁盘空间的同时,也能有效的减少磁盘IO,这也是ClickHouse查询效率更高的原因之一;另一方面ClickHouse比ES占用更少的内存,消耗更少的CPU资源。我们预估用ClickHouse处理日志可以将服务器成本降低一半。
-
相比ES,ClickHouse稳定性更高,运维成本更低。ES中不同的Group负载不均衡,有的Group负载高,会导致写Rejected等问题,需要人工迁移索引;在ClickHouse中通过集群和Shard策略,采用轮询写的方法,可以让数据比较均衡的分布到所有节点。ES中一个大查询可能导致OOM的问题;ClickHouse通过预设的查询限制,会查询失败,不影响整体的稳定性。ES需要进行冷热数据分离,每天200T的数据搬迁,稍有不慎就会导致搬迁过程发生问题,一旦搬迁失败,热节点可能很快就会被撑爆,导致一大堆人工维护恢复的工作;ClickHouse按天分partition,一般不需要考虑冷热分离,特殊场景用户确实需要冷热分离的,数据量也会小很多,ClickHouse自带的冷热分离机制就可以很好的解决。
-
ClickHouse采用SQL语法,比ES的DSL更加简单,学习成本更低。
clickhouse查询限制
| 参数 | 参考值 | 作用 |
|---|---|---|
| max_threads | 32 | 用于控制一个用户的查询线程数 |
| max_memory_usage | 10000000000 | 单个查询最多能够使用内存大小9.31G |
| max_execution_time | 30 | 单个查询最大执行时间 |
| skip_unavailable_shards | 1 | 在通过分布式表查询的时候,当某一个shard无法访问时,其他shard的数据仍然可以查询 |
如果以上查询限制还是不够的话,可以手动kill query终止慢查询的执行。