
什么是trace
分布式链路追踪技术就是如实地记录一个请求经过的所有系统的基本信息(ip、appkey、方法名)及系统间调用信息(耗时、成功失败),最终呈现为一张有向图。
在微服务架构盛行的当下,一次网络请求需要调用上百个微服务子系统。任何一个微服务子系统变慢,都会拖慢整个请求处理过程。有了trace提供的这张有向图,我们就知道一个慢请求到底是在这张图的哪个节点上遭遇了失败或者慢响应。这对于我们分析性能问题个案有很大的帮助。
什么是可观测性
可观测性是云原生时代中诞生的,传统意义上的监控侧重于知道系统不能正常工作了,可观测性侧重于知道为什么系统不能正常工作了,系统要从黑盒变成白盒,变得可观测。
metrics、trace、log被称为可观测性的三大支柱(也称三大主要信号),实际上这三个概念都是比较老的概念。但是在以前这三者是孤立的,三座信息孤岛独立发挥作用。metrics告诉你系统不能工作了,频繁失败,耗时增加。trace系统告诉你某个个案失败在哪里,耗时在哪里。Log系统则是更细粒度的debug信息,信息杂而全。下面的图描绘了metrics、trace、log包含哪些信息。在系统不可观测的传统监控时代,我们排查问题的过程是这样使用这些信息的:我们收到系统不能正常工作的告警,打开metrics系统看到某项指标成功率下降,然后找到具体个案(trace)确认这些请求从哪里来从而确认影响范围(心里有个底),最终找到个案的log,通过日志中具体的exception定位问题根因。排查问题是一个从metrics到trace,从trace到log的过程,是从宏观视角到微观视角的过程。就像校长说,这个班很差,具体到个人是xxx影响了班级的风气。
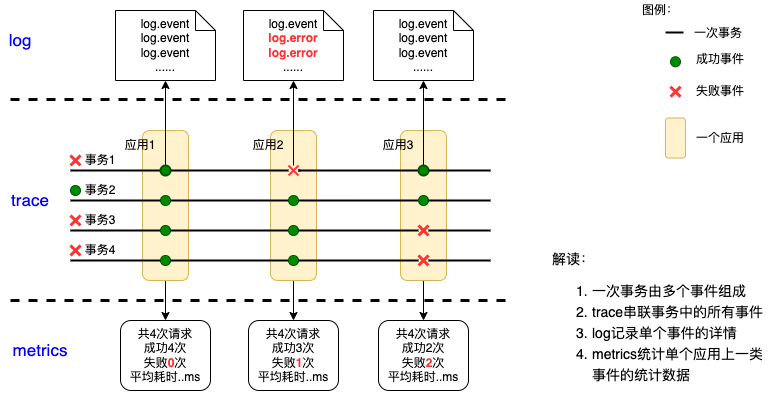
公司内部metrics、log、trace都是有的,有些小公司缺失了trace系统,有些公司缺失了trace和log系统。他们排查问题的方式就会有一定程度的退化,例如直接从metircs到log,寻找个案(trace)就靠开发同学自己了,当然这个过程也可能被省略。公司里CAT是可观测性的主力系统,排查问题一般是看到transaction成功率下降,然后到problem报表看logview找到具体原因(CAT也是可以知道系统为什么不工作的,也是可观测性系统)。logview这个东西其实就是metrics、trace、log融合的理念,如今这个理念被称为可观测性。但是logview也是有局限性的,最大的局限在于他不是分布式链路追踪,而是进程内链路追踪。
个人认为,可观测性在实践上就是打破metrics、trace、log的信息孤岛,通过metrics、trace、log关联让问题定位这件事变得自动。OpenTelemetry的可观测性白皮书是这样来做metrics、trace、log关联的:上报metrics时报文中有Exampler(良好的例子),其实就是traceId,用于关联metrics和trace。log中包含traceId、spanId,用于关联trace和log。通过这些关联字段(主要就是traceId),从metrics找trace、从trace找log,就是一件十分简单并且可以集成到paas平台的事情。
从trace生成metrics(也称为Dependency分析)
在上面介绍什么是可观测性时,已经介绍了trace承上启下关联metrics和log的能力,这是trace在“个案”分析上的作用,但并不止于此。
trace传递标记,用于分类
在单体应用时代,我们只关注应用A、应用B各自的成功率耗时是否正常;在微服务时代,我们还要关注跨服务调用的成功率耗时是否正常。这种跨进程调用监控一定需要分布式链路追踪。
把“分布式”翻译为“跨进程网络传输”,“踪”是踪迹,翻译为“标记”。“追踪”是探查的含义,跟监控的语意一致。如果不提及监控的语意,trace可以称为“跨进程网络传输标记”。很土,但是这是trace的本质。
A调用B时,标记请求来源于A,这个标记通过trace透传给B,B收到这个标记时才可以统计A调B的次数耗时等指标。
“标记”是用于分类的,标记越细粒度,分类也更细。最最常见的分类是按照来源服务进行分类,粒度更细会到按照来源ip进行分类。从业务角度看,也可以根据接口和参数识别出业务场景,根据业务场景标识进行分类。对分布式调用性能指标的监控,本质都是对分布式调用进行分类,只是分类的依据不一样。
“标记”、“分类”还有个很新潮的名字叫“流量染色”。
按类生成性能指标
分类的意义在于按类聚合(求和求平均)生成性能指标。看看sql的groupby语句,select sum(B) from table group by A,根据A分类是为了计算B的总和(sql也有规范,非groupby字段在select里一定要被聚合函数包裹)。
我们对流量进行分类后,就可以统计同一类流量的性能指标。
“分布式调用性能监控”产品的核心是根据trace传递的标记分类,并按类聚合生成总数平均值指标。设计“链路监控”产品的核心是想好用trace传递什么标记,按什么标记进行分类。
结语
本文主题是trace,先介绍了trace个案分析在可观测性体系中的作用,最后介绍了从trace生成性能指标的核心在于trace可以“跨进程网络传输分类标记”的能力。